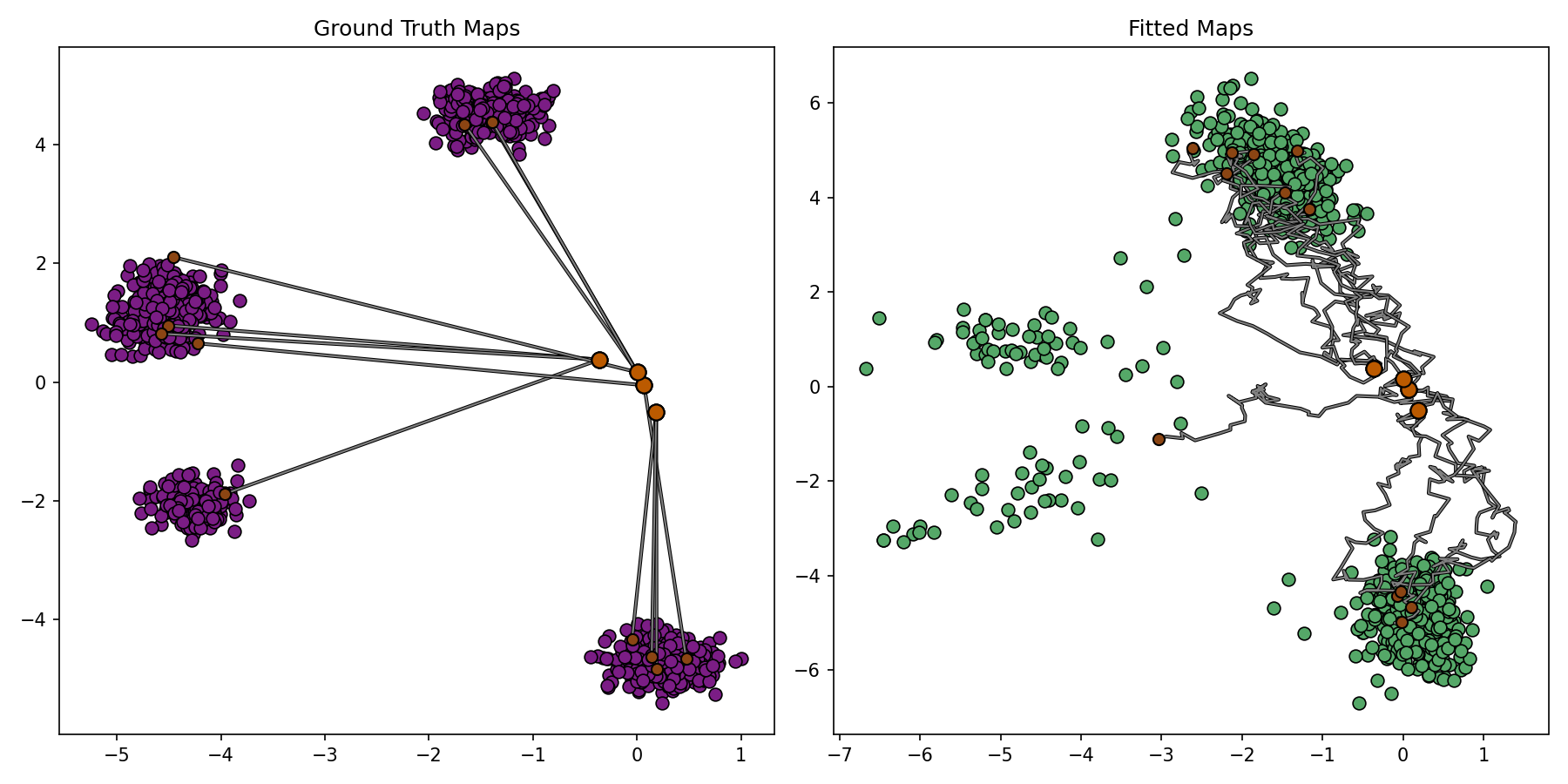
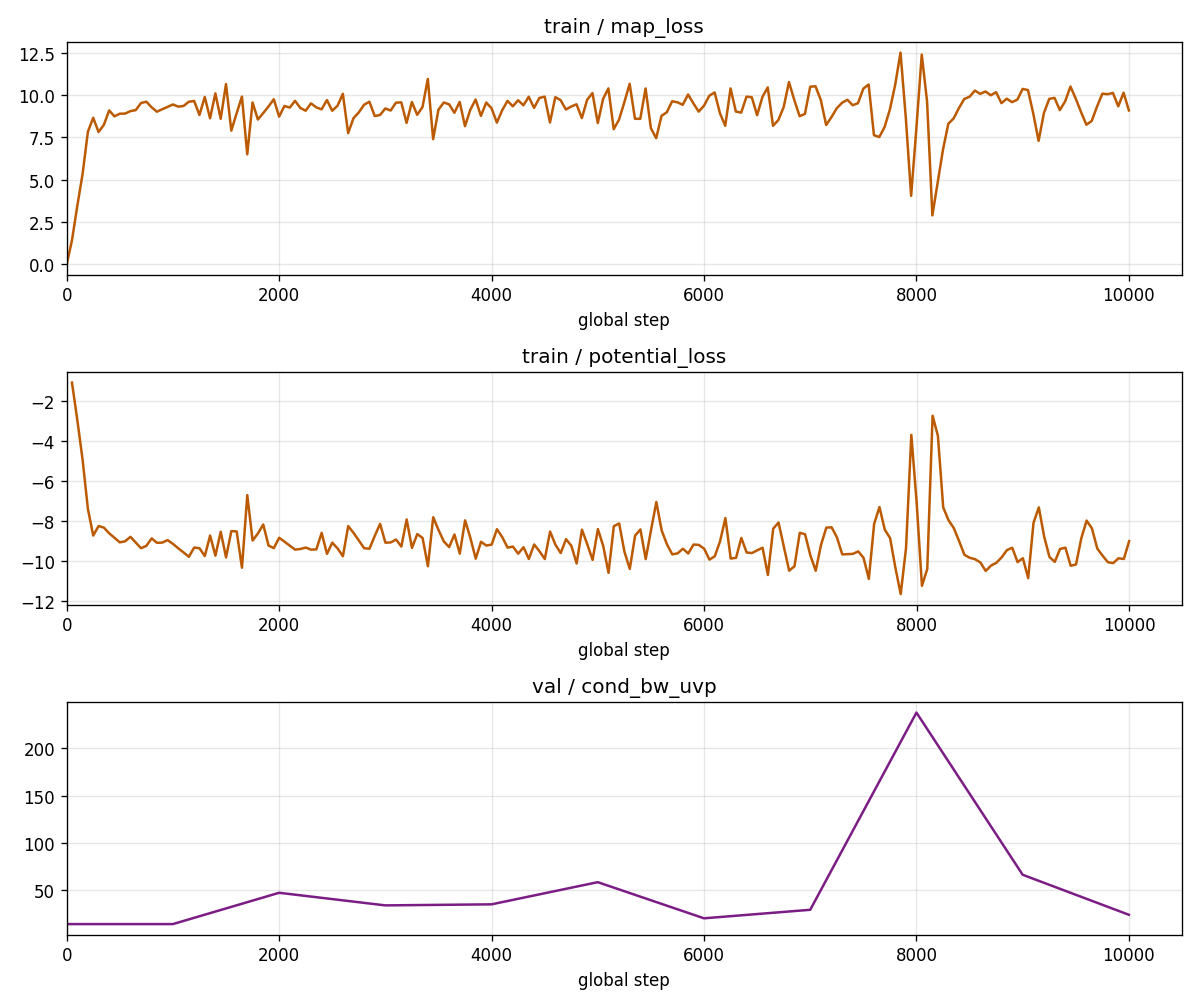
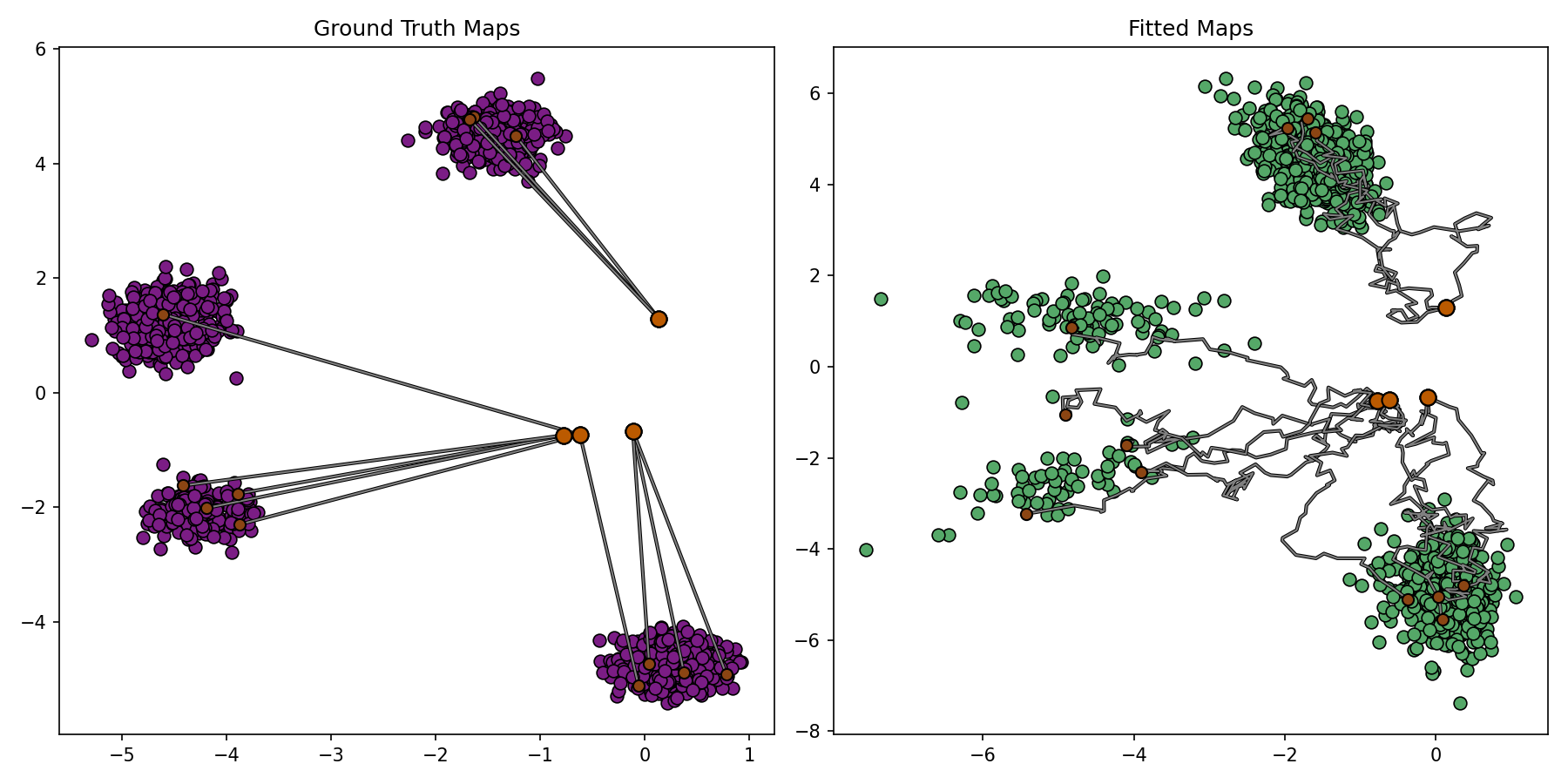
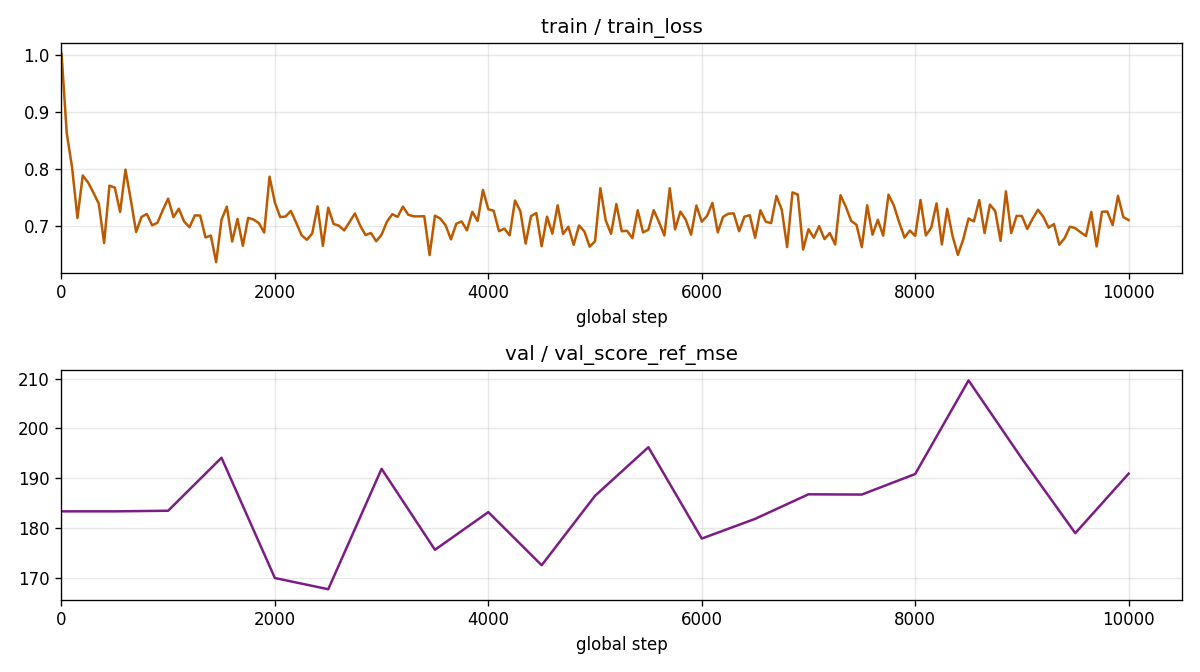
# ===========
# Hyperparameters: batch size, train steps, EM resolution, map/potential step ratio, LR.
BATCH_SIZE = # any size that fits on GPU
ITERATIONS =
SDE_STEPS = # >= 50
NUM_MAP_STEPS = # Ratio of mapping updates to potential updates
INTEGRAL_SCALE =
HIDDEN_DIM =
LR =
# ===========
datamodule = BenchmarkDataModule(
batch_size=BATCH_SIZE,
val_batch_size=256,
input_sample=input_sampler.sample,
target_sample=target_sampler.sample,
testset_x=testset_x,
testset_y=testset_y,
)
# ===========
# Drift network v_theta(x, t); input concat [x, t] so first layer is DIM + 1.
map_net = nn.Sequential(
nn.Linear(DIM + 1, HIDDEN_DIM),
nn.ReLU(),
nn.Linear(HIDDEN_DIM, HIDDEN_DIM),
nn.ReLU(),
nn.Linear(HIDDEN_DIM, HIDDEN_DIM),
nn.ReLU(),
nn.Linear(HIDDEN_DIM, DIM),
)
# ===========
# ===========
# Terminal potential beta_phi(y); scalar-output MLP.
potential_net = nn.Sequential(
nn.Linear(DIM, HIDDEN_DIM),
nn.ReLU(),
nn.Linear(HIDDEN_DIM, HIDDEN_DIM),
nn.ReLU(),
nn.Linear(HIDDEN_DIM, HIDDEN_DIM),
nn.ReLU(),
nn.Linear(HIDDEN_DIM, 1),
)
# ===========
map_opt = partial(torch.optim.Adam, lr=LR, weight_decay=1e-10)
potential_opt = partial(torch.optim.Adam, lr=LR, weight_decay=1e-10)
module = ENOT(
eps=EPS,
dim=DIM,
sde_steps=SDE_STEPS,
integral_scale=INTEGRAL_SCALE,
num_map_steps=NUM_MAP_STEPS,
num_cond_samples=1000,
conditional_sampler=conditional_sampler,
map_net=map_net,
potential_net=potential_net,
map_opt=map_opt,
potential_opt=potential_opt,
grad_clip_norm=1.0, # use float("inf") for no clipping
n_last_steps_without_noise=1, # omit diffusion on last EM steps (noise-free tail; common ENOT setup)
)
# Adjust plotter / logger / trainer options below if needed.
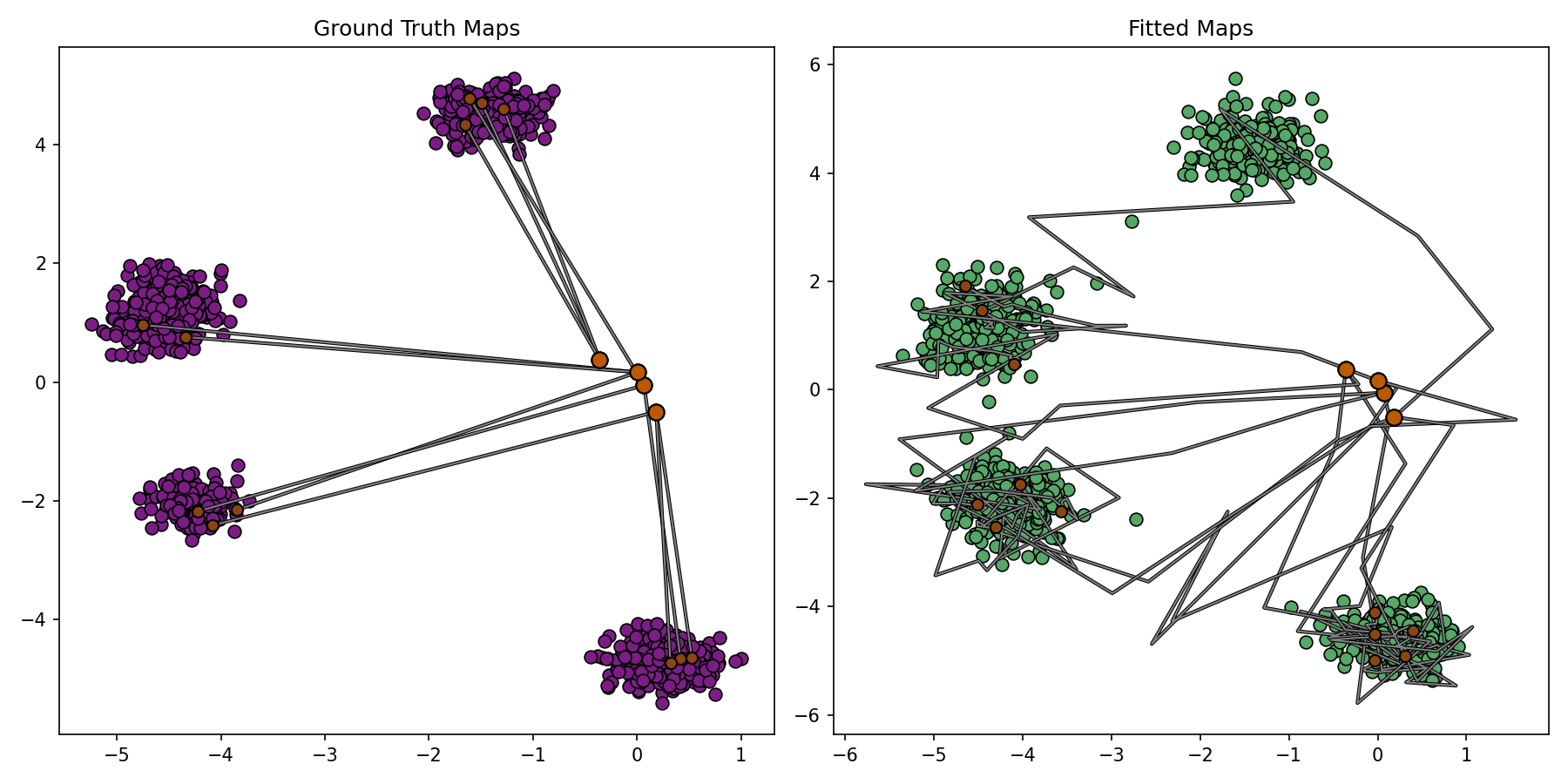
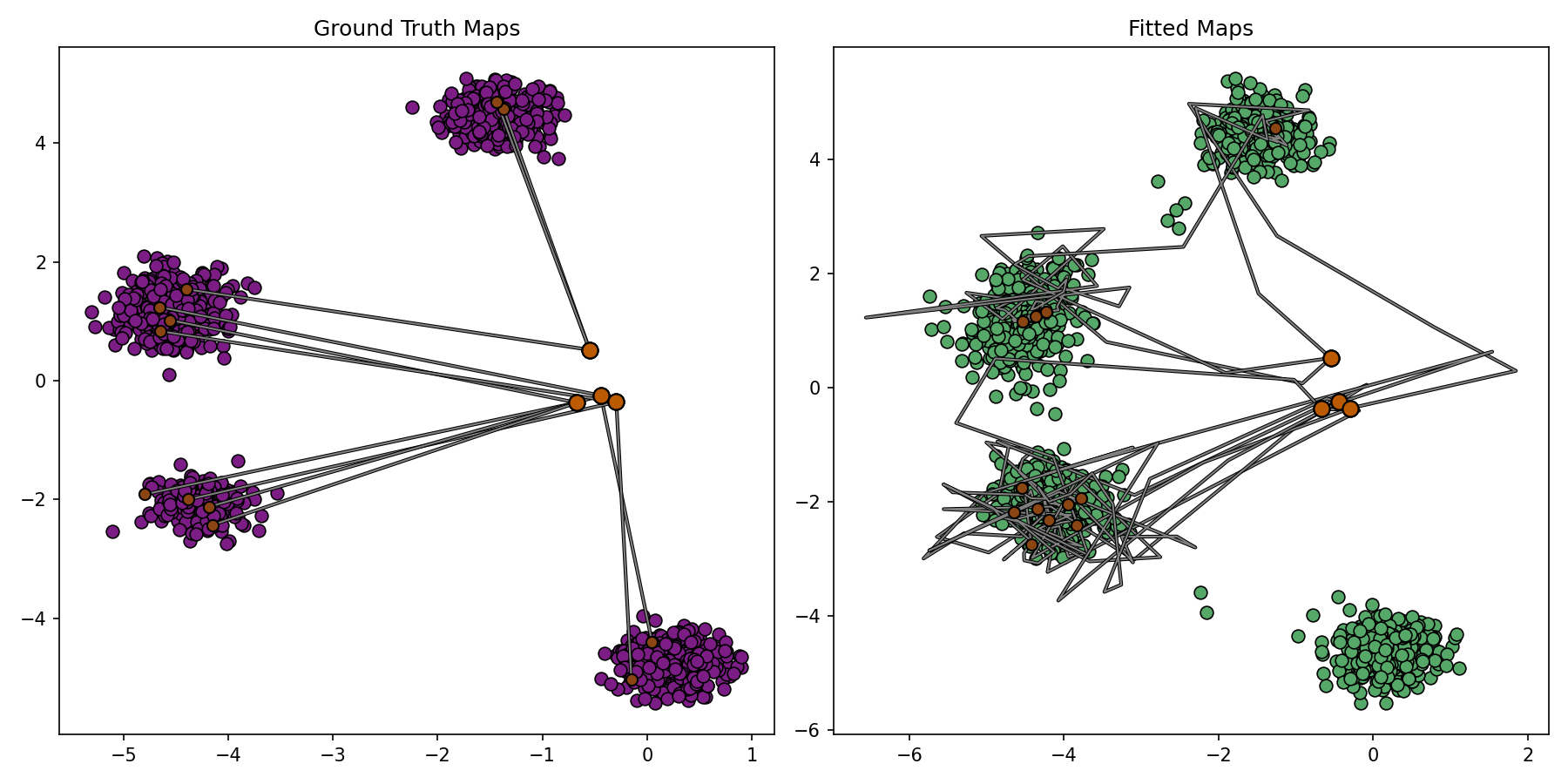
plotter_callback = BenchmarkPlotterCallback(
DIM, 1536, 4, 3, benchmark_sample=conditional_sampler.sample, notebook_display_id_prefix="cot_enot"
)
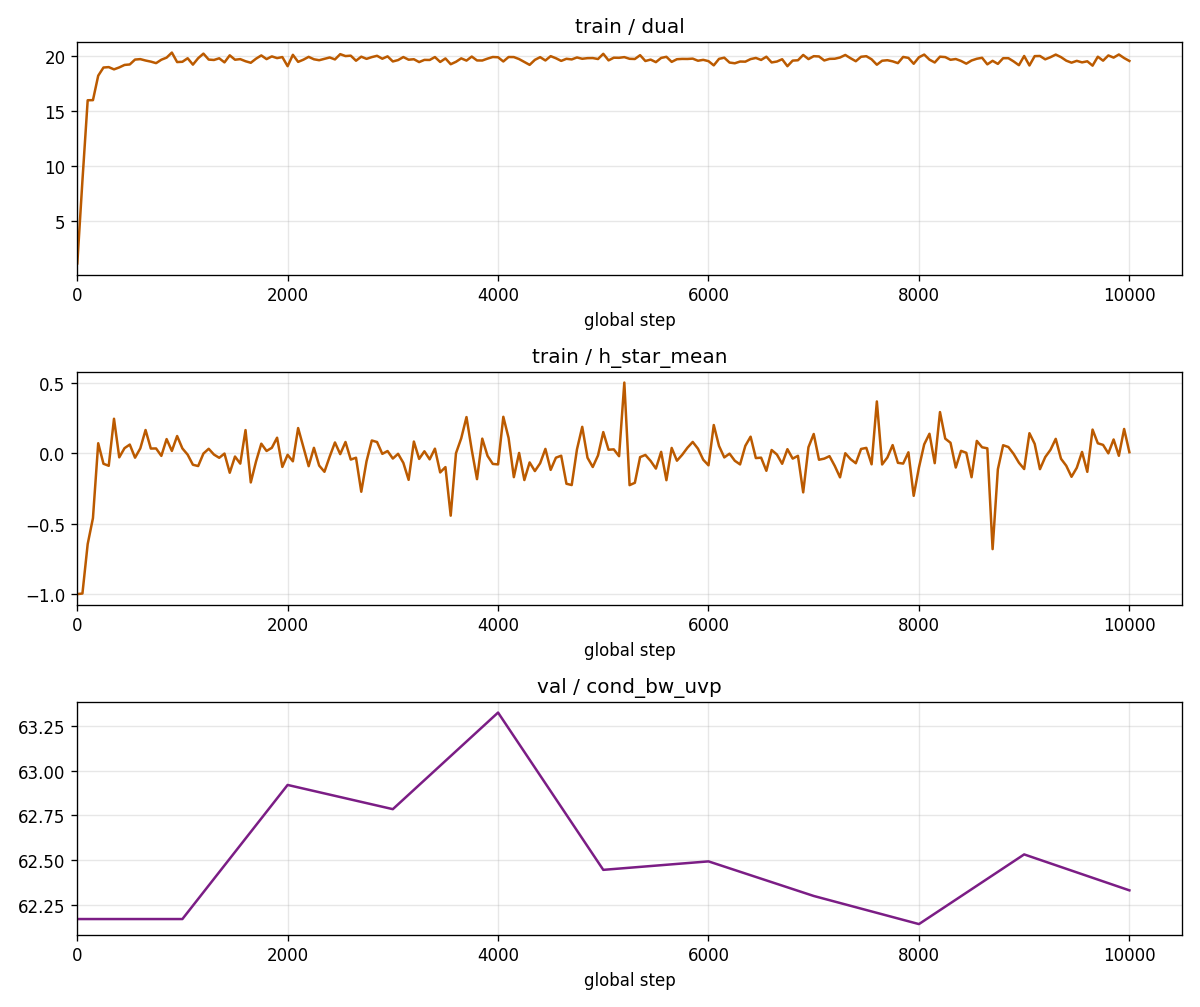
enot_loss_cb = LossCurveCallback(
train_metrics=["map_loss", "potential_loss"],
val_metrics=["cond_bw_uvp"],
train_log_every_n_steps=50,
include_step_zero=True,
notebook_display_id_prefix="cot_enot",
)
comet_logger = CometLogger(
project="cot",
name=f"enot_dim_{DIM}_eps_{EPS}",
mode="create", # new experiment each run (default get_or_create reuses same experiment)
)
trainer = Trainer(
accelerator="gpu",
max_epochs=1,
val_check_interval=1000,
callbacks=[plotter_callback, enot_loss_cb],
limit_train_batches=ITERATIONS,
enable_checkpointing=False,
logger=comet_logger,
log_every_n_steps=50,
)
trainer.fit(module, datamodule=datamodule)